Yan Zheng, Zhengyang Hou, Göran Ståhl, Ronald E. McRoberts, Weisheng Zeng, Erik Næsset, Terje Gobakken, Bo Li, Qing Xu. Nexus of certain model-based estimators in remote sensing forest inventory[J]. Forest Ecosystems, 2024, 11(1): 100245. DOI: 10.1016/j.fecs.2024.100245
Citation:
Yan Zheng, Zhengyang Hou, Göran Ståhl, Ronald E. McRoberts, Weisheng Zeng, Erik Næsset, Terje Gobakken, Bo Li, Qing Xu. Nexus of certain model-based estimators in remote sensing forest inventory[J]. Forest Ecosystems, 2024, 11(1): 100245. DOI: 10.1016/j.fecs.2024.100245
Yan Zheng, Zhengyang Hou, Göran Ståhl, Ronald E. McRoberts, Weisheng Zeng, Erik Næsset, Terje Gobakken, Bo Li, Qing Xu. Nexus of certain model-based estimators in remote sensing forest inventory[J]. Forest Ecosystems, 2024, 11(1): 100245. DOI: 10.1016/j.fecs.2024.100245
Citation:
Yan Zheng, Zhengyang Hou, Göran Ståhl, Ronald E. McRoberts, Weisheng Zeng, Erik Næsset, Terje Gobakken, Bo Li, Qing Xu. Nexus of certain model-based estimators in remote sensing forest inventory[J]. Forest Ecosystems, 2024, 11(1): 100245. DOI: 10.1016/j.fecs.2024.100245
The Key Laboratory for Silviculture and Conservation of Ministry of Education, Beijing Forestry University, Beijing, 100083, China
b.
Ecological Observation and Research Station of Heilongjiang Sanjiang Plain Wetlands, National Forestry and Grassland Administration, Shuangyashan, 518000, China
c.
Department of Forest Resource Management, Swedish University of Agricultural Sciences, Umeå, Sweden
d.
Department of Forest Resources, University of Minnesota, St. Paul, Minnesota, United States
e.
Academy of Forest Inventory and Planning, National Forestry and Grassland Administration, Beijing, 100714, China
f.
Faculty of Environmental Sciences and Natural Resource Management, Norwegian University of Life Sciences, P.O. Box 5003, 1432, Ås, Norway
g.
Department of Statistics, University of Illinois at Urbana-Champaign, Champaign, IL, United States
h.
Key Laboratory of National Forestry and Grassland Administration/Beijing for Bamboo & Rattan Science and Technology, International Center for Bamboo and Rattan, Beijing, 100102, China
Funds:
the National Social Science Fund of China22BTJ005
the Key Project of National Key Research and Development Plan2023YFF1304002-05
the National Natural Science Foundation of China32001252
the International Center for Bamboo and Rattan1632022024
the International Center for Bamboo and Rattan1632020029
the International Center for Bamboo and Rattan1632021024
The Key Laboratory for Silviculture and Conservation of Ministry of Education, Beijing Forestry University, Beijing, 100083, China. E-mail address: houzhengyang@bjfu.edu.cn (Z. Hou)
Remote sensing (RS) facilitates forest inventory across a wide range of variables required by the UNFCCC as well as by other agreements and processes. The Conventional model-based (CMB) estimator supports wall-to-wall RS data, while Hybrid estimators support surveys where RS data are available as a sample. However, the connection between these two types of monitoring procedures has been unclear, hindering the reconciliation of wall-to-wall and non-wall-to-wall use of RS data in practical applications and thus potentially impeding cost-efficient deployment of high-end sensing instruments for large area monitoring. Consequently, our objectives are to (1) shed further light on the connections between different types of Hybrid estimators, and between CMB and Hybrid estimators, through mathematical analyses and Monte Carlo simulations; and (2) compare the effects and explore the tradeoffs related to the RS sampling design, coverage rate, and cluster size on estimation precision. Primary findings are threefold: (1) the CMB estimator represents a special case of Hybrid estimators, signifying that wall-to-wall RS data is a particular instance of sample-based RS data; (2) the precision of estimators in forest inventory can be greater for stratified non-wall-to-wall RS data compared to wall-to-wall RS data; (3) otherwise cost-prohibitive sensing, such as LiDAR and UAV, can support large scale monitoring through collecting RS data as a sample. These conclusions may reconcile different perspectives regarding choice of RS instruments, data acquisition, and cost for continuous observations, particularly in the context of surveys aiming at providing data for mitigating climate change.
To meet net-zero goals by mitigating the net release of greenhouse gases, the United Nations Framework Convention on Climate Change mandates annual estimates of biotic and abiotic variables of interest (VOIs) for monitoring emissions from the land-use, land-use change, and forestry sector (COP 21, 2015; IPCC, 2018). Additionally, the Food and Agriculture Organization of the United Nations underscores the importance of conducting forest inventories at local, regional, national, or global levels (FAO, 2024). Many countries’ National Forest Inventory (NFI) program readily offer precise estimates of this sort every five years using stratified or other probability sampling procedures, categorized as design-based inference (Tomppo et al., 2010). However, it is difficult and expensive for these programs to meet precision standards for annual reporting, as the annual sample size of observations for a VOI in, e.g., the US and China is only one fifth of the full sample size of just over 400,000 plots, despite being spatially balanced (Vidal et al., 2016; Hou et al., 2021). This small sample size problem challenges monitoring efficiency and reliability because design-based inference relies on large sample sizes for adequate precision (Cochran, 1977; Särndal et al., 1992).
Model-based inference can be a remedy for small sample size problems (Faber and Fonseca, 2014; Vandendijck et al., 2016). In comparison to design-based inference, it can offer a higher level of precision with the same sample size, or alternatively, a similar level of precision with a smaller sample size (Hou et al., 2019, 2023). Model-based inference is based on the concept of a population generated by a superpopulation model (Chambers and Clark, 2012). Conceptually it is quite different from design-based inference. The latter mode of inference asserts that the population studied is fixed, but unknown. Probability theory applies because we select random samples of population elements, based on which we infer properties of the population (Gregoire, 1998). In model-based inference, probability theory applies because the superpopulation model generates random populations; however, the population elements and associated auxiliary data remain constant under standard conditions (Graubard and Korn, 2002); it is only the VOIs for the population elements that vary. This inference paradigm does not require probability sampling for observing y and X during the model construction phase. Nevertheless, probability sampling ensures resilience against deviations from the assumed proxy superpopulation model with a sample that is balanced or representative in X (Chambers and Clark, 2012). A sample that is balanced in X is one where the sample mean of the X-values approximates the population mean of the X-values (Thompson, 2012).
Remote sensing (RS) has made it possible to conduct forest inventory through use of conventional model-based (CMB) inference. The CMB estimator can produce accurate estimates not only in a timely manner but also at various geographical scales (McRoberts et al., 2006, 2013, 2018). However, the CMB estimator necessitates remotely sensed auxiliary variables, X, available wall-to-wall, meaning available for every element of a population under consideration (Hou et al., 2018). This full RS coverage requirement poses a challenge for cost-efficient monitoring at national, provincial, or even county levels using advanced instruments such as high-resolution spectral or LiDAR sensors, and thus acts as a barrier to achieving information for pursuing net-zero objectives. Solutions need to be explored.
Hybrid estimators potentially offer feasible solutions. These estimators are compatible with non-wall-to-wall X selected using probability sampling and are considered as special instances of model-based inference (Ståhl et al., 2016). There are two distinct phases involved in Hybrid estimation. The first phase involves probability sampling of X, while model-based principles are applied to the second phase, and the two phases are independent of each other (Ståhl et al., 2011). However, while Hybrid estimation does support non-wall-to-wall X in the form of RS sample observations, these estimators are design-specific with (1) general properties and connections to the CMB estimator that merit further investigation; and (2) specific impacts of sampling design, RS cluster size, and coverage rate for non-wall-to-wall auxiliary data, that are not yet fully understood. Understanding the nexus of these factors could lead to increased precision and reduced costs in practical applications.
Consequently, our objectives are to (1) shed further light on the connections between different Hybrid estimators, and between CMB and Hybrid estimators, through analytical assessment and Monte Carlo simulations; and (2) compare the effects and explore the tradeoffs related to the sampling design, coverage rate, and RS cluster size on estimation precision.
2.
Model-based theories to support remote sensing forest inventory
2.1
Overview
Model-based estimators utilize a proxy of the superpopulation model for the relationship between the VOI and the auxiliary variables, X, to estimate or predict parameters for the real-world population, such as the population mean, μ, or total, τ, for the VOI (Hansen et al., 1983). Based on the remotely sensed X being wall-to-wall or not, there are at least two types of estimators used in model-based inference: the CMB estimator and Hybrid estimators. The CMB estimator requires wall-to-wall X, while Hybrid estimators can work with non-wall-to-wall X selected by probability sampling. This section will first introduce four model-based estimators, and then illustrate their connection and integration through transiting from sampling of auxiliary data to wall-to-wall coverage, and through estimator transformation. The analytical discoveries are empirically examined with Monte Carlo simulations in Section 3. The findings may benefit both theory and practice, facilitating broader use of model-based inference for remote sensing-assisted forest inventory.
With wall-to-wall or sample-based acquisition of X, we consider four cases, as listed in Table 1.
Table
1.
The four cases of wall-to-wall or sample-based acquisition of X.
These four model-based estimators are based on four foundational assumptions: (Ⅰ) a target population U comprises N elements; (Ⅱ) a sample S1 selected from U contains m elements, with each element having remotely sensed auxiliary variables, X, observed, except for the Hybrid estimator for cluster or stratified sampling of X where m represents the number of clusters, each containing A elements; (Ⅲ) a sample S2 containing n2 elements for which each element has both y and X observed; (Ⅳ) the sample S2 divides into S2_1 (containing n2_1 elements), S2_2 (containing n2_2 elements) and so on due to stratum-specific modeling in Case B.3. The cluster size is denoted by A, and the remote sensing coverage rate by the sampling intensity of S1, i.e., mA/N.
2.2
Conventional model-based estimator for wall-to-wall X
The CMB estimator utilizes a model to predict μ or τ of a VOI. Our study specifically focuses on μ, because τ is then straightforwardly derived as τ=Nμ. The model may be linear or nonlinear and can be expressed as the general expression, yi=g(xi,α)+εi, where yi represents the VOI value in the ith element of the population, xi is a vector of remotely sensed auxiliary variables, α is a vector of model parameters, and εi is a random error.
The point estimator, ˆμ1, is simply the mean of wall-to-wall predictions using a fitted model, expressed as
ˆμ1=1NN∑i=1g(xiU,ˆαS2)
(1)
where xiU denotes a vector of remotely sensed auxiliary variables for the ith element in the population U of size N, i.e., wall-to-wall X; and ˆαS2 is a vector of model parameters estimated using sample S2. Section 2.6 provides details about the modeling and estimation of model parameters.
The variance of ˆμ1 can then be obtained through Taylor series approximation. If ˆαS2 is reasonably accurate, we can linearize the g(·) model at true α, i.e., g(xiU,ˆαS2)≈g(xiU,α)+(ˆαS21−α1)g1', where is a partial derivative with respect to the of p model parameters, and then use the second moment of the linearized function to approximate the variance of (Ståhl et al., 2011).
Thereby, the variance estimator of , , is derived as
where is the estimated covariance matrix for with the sample, and is the mean of the first-order partial derivatives requiring remotely sensed wall-to-wall auxiliary variables.
2.3
Hybrid estimator for simple random sampling of X
Simple random sampling is straightforward to utilize, relatively efficient for surveying both homogenous and heterogeneous populations, although it can be expensive in terms of logistics or acquisitions due to random selection of element locations (Daniel, 2011). When simple random sampling is employed to select X of size m from U, i.e., , the point estimator, , is expressed as (Ståhl et al., 2011)
where represents a vector of remotely sensed auxiliary variables for the element in the sample of size m, i.e., non-wall-to-wall X, selected by simple random sampling without replacement; and is the same as in Section 2.2.
To derive the variance of , both the sampling of and the distribution of are considered. Since is independent of due to the independency of phases, is independent of . Given that is unbiased or approximately so, then , where accounts for sampling and for modeling. Because the two components, and , are uncorrelated, the variance of is the sum of each component's variance, expressed as , where is the population variance of values; only depends on the sample of ; and . The first term of arises from the sampling uncertainty due to , and the second term from the model variance. The finite-population correction factor, , decreases , but can be disregarded for populations that are large compared to the sample size of (Patterson et al., 2019). Elaborate derivations can be found in Ståhl et al. (2011, Appendix).
Thereby, the variance estimator of , , is expressed as
where is the sample variance of prediction; is the same as in Section 2.2; and applies to . Notably, both the sample size of and the model may affect .
2.4
Hybrid estimator for cluster sampling of X
Cluster sampling is a cost-effective and time-efficient method due to the surveying of nearby elements in a cluster. It is especially efficient for homogeneous populations but less so for heterogeneous ones. When using cluster sampling to select X in the form of m clusters by simple random sampling without replacement, and each cluster contains A elements, i.e., , the point estimator, , is expressed as (Ståhl et al., 2011)
where is the total of prediction for A elements in the cluster of .
Following the same logic as in Section 2.3, the variance of can be derived as , where is the population variance of cluster totals based on values; . Likewise, the first term of arises from the sampling uncertainty due to , and the second term from the model variance.
Thereby, the variance estimator of , , is expressed as
where is the sample variance of cluster totals based on prediction at the element level; and is estimated with ; and . Note that (1) is consistent with Sections 2.2 and 2.3, and (2) the sample size of and the model may affect through either or both terms.
2.5
Hybrid estimator for stratified sampling of X
Stratified sampling is an effective method for surveying diverse populations, despite being somewhat labor-intensive in terms of stratification and computation, which can lead to increased costs (Næsset et al., 2013). In this approach, population elements are grouped into distinct strata based on similarities in a discrete variable correlated with the VOI, such as classes for forest cover, land use, or terrain (Gregoire and Valentine, 2007). Each stratum contains sample elements which allow for the estimation of a stratum-wise mean using a stratum-wise estimator. These stratum-wise estimates can then be weighted and combined to estimate the population mean.
When stratified sampling is utilized to select X in the form of m clusters via simple random sampling without replacement from respective strata, and each cluster contains A elements, i.e., , the point estimator, , is expressed as (Ståhl et al., 2011)
where is the weight for stratum h, which is computable using a discrete variable and is used for stratification (Bechtold and Patterson, 2005); and are the numbers of population and sample elements within stratum h. is the mean estimator of the stratum with notations consistent with . is the sum of the element level model prediction for A elements of the cluster, and is the estimated model parameters used for stratum h. Note that this element level model can either be a global model constructed with , or a set of stratum-specific models constructed with , and so forth of respective strata.
Following the same logic as in Sections 2.3 and 2.4, the variance of divides into sampling and modeling components, expressed as . Likewise, the first term of arises from the sampling uncertainty due to , and the second term from the model variance.
Thereby, the variance estimator of , , is expressed as
where importantly, the cross-stratum covariance in the second term is zero if stratum-specific models are used, and non-zero if a global model is used (Ståhl et al., 2011); . In case stratum-specific variance is of interest, this estimator is expressed as . Note that this formula considers that samples may be selected, or models may be applied, in a way so that dependencies among strata arise, as may be the case in applications where samples of RS data extend across several strata or where the same model has been applied in several or all strata.
2.6
Modeling
Both global and stratum-specific models were developed at the element level. The global model applies to Cases A and B, while the stratum-specific models only apply to Case B.3 in Table 1. With sample , the global model takes the form of where and denotes a vector of model parameters to be estimated. This model illustrates the connection between the dependent VOI, (i.e., , and remotely sensed independent variables, (i.e., ). Similarly, stratum-specific models depict stratum-specific relationships: with sample , where ; and with sample , where .
In model-based inference, these models may be linear or nonlinear, and involve different independent variables. However, for the sake of comparability and simplicity, a linear model using the same independent variables selected through “bootstrap stepAIC” procedure (Rizopoulos, 2022) was adopted: , where corresponds to , or in the global and stratum-specific models; is a design matrix; with a positive definite matrix corresponding to , or .
The vector of model parameters was estimated with weighted least squares to accommodate heteroscedasticity (Carroll and Ruppert, 1988). It has the form , where is a diagonal matrix with elements estimated using a variance function fitted with a four-step procedure detailed in McRoberts et al. (2016). The variance-covariance matrix of was estimated with a robust HCCM estimator that attenuates the effects of leverage points (Furno, 1996), , a key term inserted into Eqs. 2, 4, 6 and 8 for quantifying model variance. Dividing by inflates so that the over-influence of observations with large variance is adjusted.
Despite employing the same modeling procedures, the estimates of and still vary for the global and stratum-specific models, depending on whether the sample is , or . The prediction accuracy of the global model was evaluated utilizing the root mean square error, , and its relative form , where denotes the sample mean of field observed VOI in . Similarly, and were calculated for stratum-specific models by substituting the subscript with or , and by substituting the sample size with or .
3.
Monte Carlo simulations
3.1
Procedures
Monte Carlo simulation encompasses a wide range of computational algorithms that utilize repeated sampling to acquire numerical outcomes (Harrison, 2010). Through the law of large numbers, the fundamental idea is to employ randomness in addressing problems inherent in probability. While the specific procedures may differ, they generally involve four steps: (1) defining a population of potential inputs, (2) randomly generating inputs from a probability distribution across the population, (3) conducting a deterministic computation on the inputs, and (4) consolidating the results (Kalos and Whitlock, 2009).
In this research, we utilized Monte Carlo simulation to validate and compare CMB and Hybrid estimators. The population is introduced in Section 3.2. Remotely sensed auxiliary variables, X, were available wall-to-wall. They were used as such in the case of CMB, but as non-wall-to-wall for Hybrid estimation. Probability samples of X were selected through sampling methods such as simple random sampling, cluster sampling, and stratified sampling. The population mean and variance estimates for a specific design were calculated with corresponding and . The second and third steps were iterated a thousand times to produce averaged estimates, and , thereby approximating and , while considering the stochastic variability inherent in sampling X. However, the crucial matter is not the quantity of repetitions, but instead the stability of the estimates. In this study, the repetitions were considered adequate as the final average of estimates across replications did not vary by more than 0.005 proportionally from any of the previous 25 averages across replications (McRoberts et al., 2023).
The remote sensing coverage rate can be represented by the sampling intensity of , i.e., , and the remote sensing cluster size A. To investigate the impact of remote sensing coverage on Hybrid estimation, we analyzed seven different sampling intensities for sampling X in various designs. Namely, containing 720, 1,440, 3,600, 7,200, 14,400, 28,800, or 120,409 elements, corresponding to sampling intensity at 0.6%, 1.2%, 3%, 6%, 12%, 24%, or 100%. Higher sampling intensities result in greater remote sensing coverage, but also lead to higher costs. With simple random sampling of X where , m is 720, 1,440, 3,600, 7,200, 14,400, 28,800, or 120,409. With cluster sampling of X, m depends on A, e.g., at sampling intensity 0.6%.
To assess the impact of remote sensing cluster size on Hybrid estimation, we investigated six different cluster sizes, i.e., A containing 1, 2, 3, 4, 5, or 6 elements for cluster sampling of X. Larger cluster sizes make logistics easier compared to simple random sampling, especially for terrestrial laser scanning. For instance, with cluster sampling of X, the cluster size A contains 1, 2, 3, 4, 5, or 6 elements, resulting in m being 720, 360, 240, 180, 144, or 120 at the sampling intensity of 0.6%. Likewise, same rule about A and m applies to the stratified sampling of X.
3.2
Population and samples
The target population sits in Kou, Burkina Faso (Fig. 1), with a population size of elements, each covering an area of 30 m by 30 m. A field campaign was conducted to observe 160 sample plots between November 2013 and February 2014, following the protocols of the Land Degradation Surveillance Framework (Vågen et al., 2013). Table 2 presents the sample statistics.
The VOI represented the density of firewood volume (m3·ha−1). A substantial portion of the local populace relies on subsistence agriculture and livestock farming, which are heavily dependent on the natural goods provided by trees, such as timber, firewood, medicinal plants, and animal fodder. Firewood alone accounts for approximately 90% of the total energy supply (Brännlund et al., 2009). The firewood volume in each sample plot includes both fallen and standing deadwood as well as living trees, selecting only the non-rotten, viable woody material for fuelwood. The density of firewood volume (m3·ha−1) was subsequently calculated for each sample plot by dividing this plot-level firewood volume by a factor of 0.09. Due to the lack of specific allometric models for the volume of particular tree species, a generalized model for dry climates as described by Chave et al. (2005) was employed.
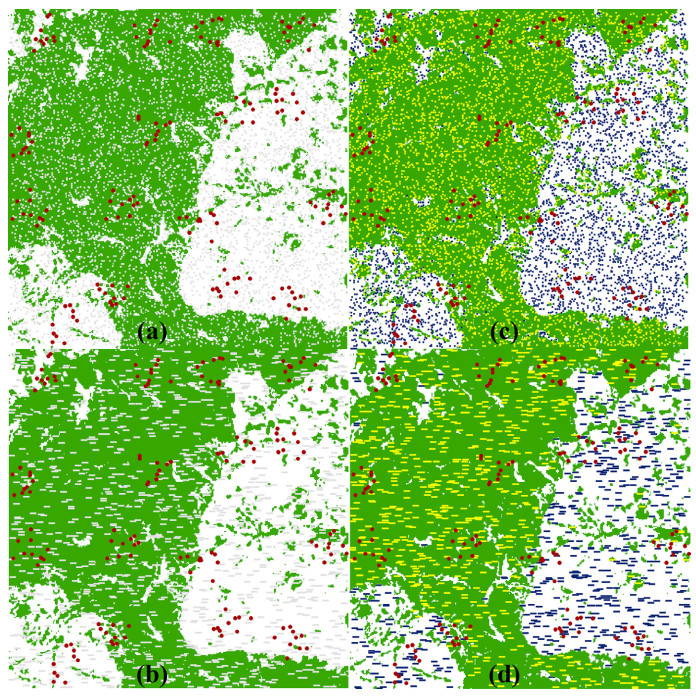
Utilizing unsupervised maximum likelihood classification (Richards, 2022), the population was categorized into dense or sparse forest cover, resulting in specific weights and samples for and (Fig. 1). The weights were 57.5% for the dense and 42.5% for the sparse forest cover areas. The sample sizes for , and in the population, dense stratum, and sparse stratum, were , and , respectively. Fig. 2 illustrates spatial layouts for samplings X at 6% coverage. For resembling scanline patterns of ALS or UAV, a cluster consists of elements in a linear formation.
Figure
2.
Illustration of the spatial layout of and . Subplot (a) demonstrates a simple random sample of X, subplot (b) shows cluster sampling of X, and subplots (c & d) exhibit stratified sampling of X, each at a 6% coverage rate. A cluster in subplots (b & d) includes six elements arranged linearly, mirroring scanline patterns for ALS or UAV. comprises elements in grey in (a) and (b), and in yellow for dense stratum and blue for sparse stratum in (c) and (d); consists of elements in red, representing sample plots from Fig. 1. (For interpretation of the references to colour in this figure legend, the reader is referred to the Web version of this article.)
RapidEye imagery (RE) was acquired at a cost of 1.3 USD·km−2, georeferenced to WGS84/UTM Zone 48N, and processed to Level-3A with a resampled spatial resolution of 30 m. Candidate independent variables used in modeling were calculated for RE, including the first principal component of the spectral bands (PCA), the textures of PCA, spectral features as detailed in Table 3 (www.indexdatabase.de), and the textures of spectral features. Texture calculations included the mean, variance, homogeneity, contrast, dissimilarity, entropy, angular second moment, and correlation (Haralick et al., 1973).
Table
3.
Spectral features obtained from RapidEye imagery.
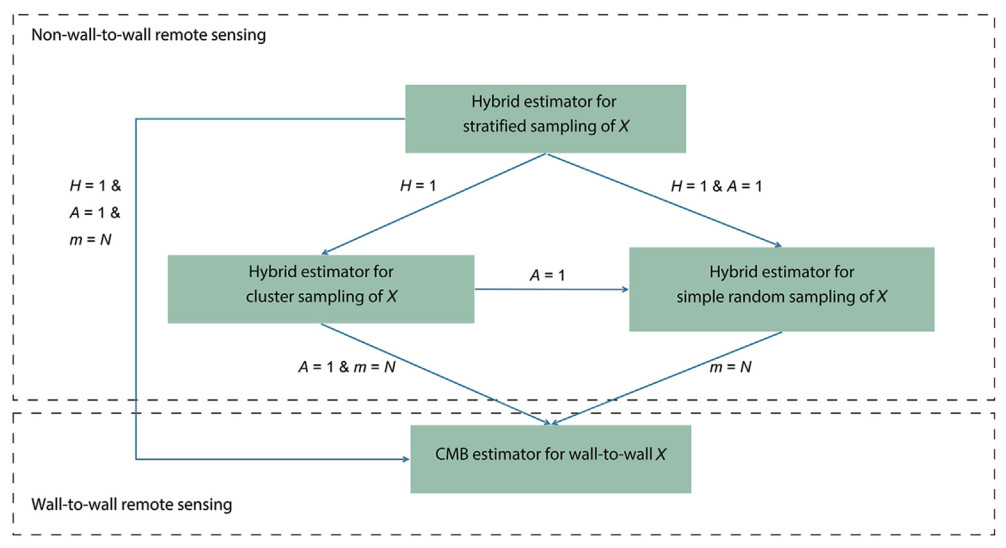
Appendix A.1 and A.2 demonstrate mathematically the connections between CMB and Hybrid estimators and the connections among Hybrid estimators. The nexus of these model-based estimators can be summarized as follows: (1) the CMB estimator for wall-to-wall X is a specific instance of the Hybrid estimator for simple random sampling of X; (2) the Hybrid estimator for simple random sampling of X is a specific instance of the Hybrid estimator for cluster sampling of X; (3) the Hybrid estimator for simple random sampling of X is a specific instance of the Hybrid estimator for stratified sampling of X; (4) the Hybrid estimator for cluster sampling of X is a specific instance of the Hybrid estimator for stratified sampling of X.
Evidently, the Hybrid estimator for stratified sampling of X is expressed in form that can be applied in multiple cases, regardless of whether the remotely sensed auxiliary variable is available wall-to-wall or non-wall-to-wall. Alternative estimators take on forms derived from this general estimator based on various sampling considerations in the acquisition of X.
Empirical results (Appendix B) of Monte Carlo simulations confirmed the analytical findings above. Fig. 3 provides an overview of these connections along with conditions outlined for equivalence. The Hybrid estimator for stratification of X represents the most general form of the scrutinized model-based estimators. Other estimators for sampling X in different ways can be derived from this general formula. Further, CMB represents a specific instance of Hybrid estimation.
Figure
3.
Nexus and integration of model-based estimators through converting the sampling of remotely sensed auxiliary variables (X) from a population of size N by the number of strata (H), the number of elements in a cluster (A), and the number of clusters (m). With simple random sampling of X, holds, making m collapse to the number of elements. With remote sensing, wall-to-wall coverage is expressed by , non-wall-to-wall coverage by , and the cluster size by A.
The rationale behind Fig. 3 can be applied to hierarchical model-based estimation (HMB). HMB, while not included, is a variation of CMB that breaks down the mean and variance estimators into multiple components to integrate a nested model constructed to utilize simple randomly selected, non-wall-to-wall but high-quality X (Saarela et al., 2020). The essence of HMB is to reduce CMB variance by increasing the sample size of y, not by increasing field observations, but by increasing the predicted y-values of a nested model (Saarela et al., 2022). The more accurate the predicted y-values, the more efficient the HMB estimation (Chen et al., 2023).
Based on Fig. 3, we hypothesize that a combination of Hybrid and HMB estimation can be derived to account for alternative samplings and sampling variabilities of X in the HMB process. This combination would encompass the advantages of both approaches by (1) supporting wall-to-wall mapping, (2) leveraging the strength of high-quality but non-wall-to-wall X, and (3) quantifying the uncertainty associated with sampling X (Saarela et al., 2023).
4.2
Constructed models
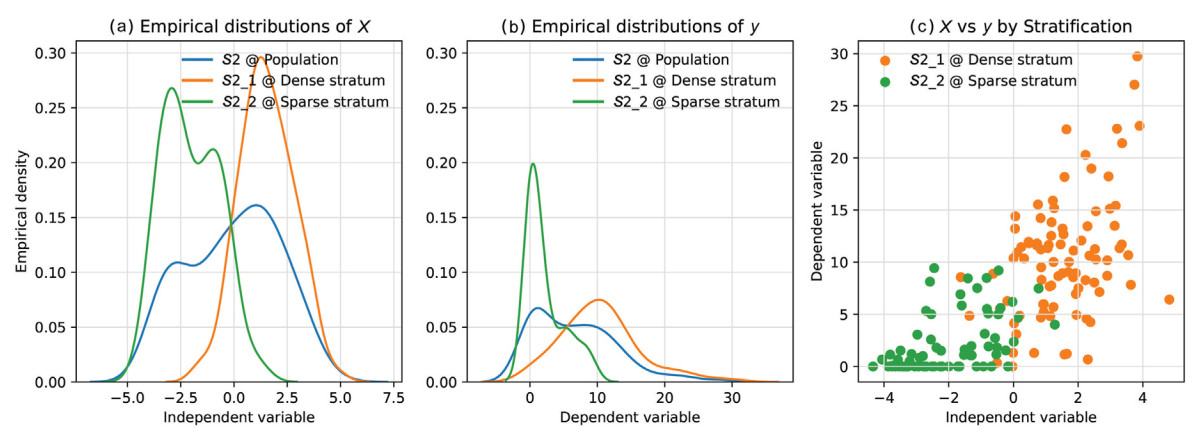
Sample balancing is associated with non-informative sampling and is a prerequisite for assuring effectiveness of model-based inference (Chambers and Clark, 2012). The samples , , and were well-spread on the independent variable, PCA, of respective models in Table 4. With balanced samples, the sample means of PCA are close to the population or stratum-specific means of PCA. In our case, sample means of PCA were −0.04, 1.54 and −2.01 for , , and , and the population, dense stratum, and sparse stratum means, of PCA were −0.04, 1.33, and −1.89, respectively. Note that alternative classification algorithms might further improve such balancing in the respective strata (Rother et al., 2004; Silva et al., 2018). When independent variable is linearly related to y, this balancing helps to yield a more precise estimate for population parameters (Grafström and Schelin, 2014). Fig. 4 delineates covariations between dependent and independent variables at the population and stratum-levels, suggesting useful classification by forest cover.
Table
4.
Constructed global and stratum-specific models.
Model
Independent variable
RMSE (m3·ha–1)
RMSE%
Global
(Intercept)
6.72
0.34
4.35
64.18
PCA
1.95
0.11
Dense
(Intercept)
7.58
0.73
5.22
50.09
PCA
1.85
0.41
Sparse
(Intercept)
4.19
0.62
2.45
111.44
PCA
0.99
0.19
All parameter estimates were significantly different from zero at significance level 5%.
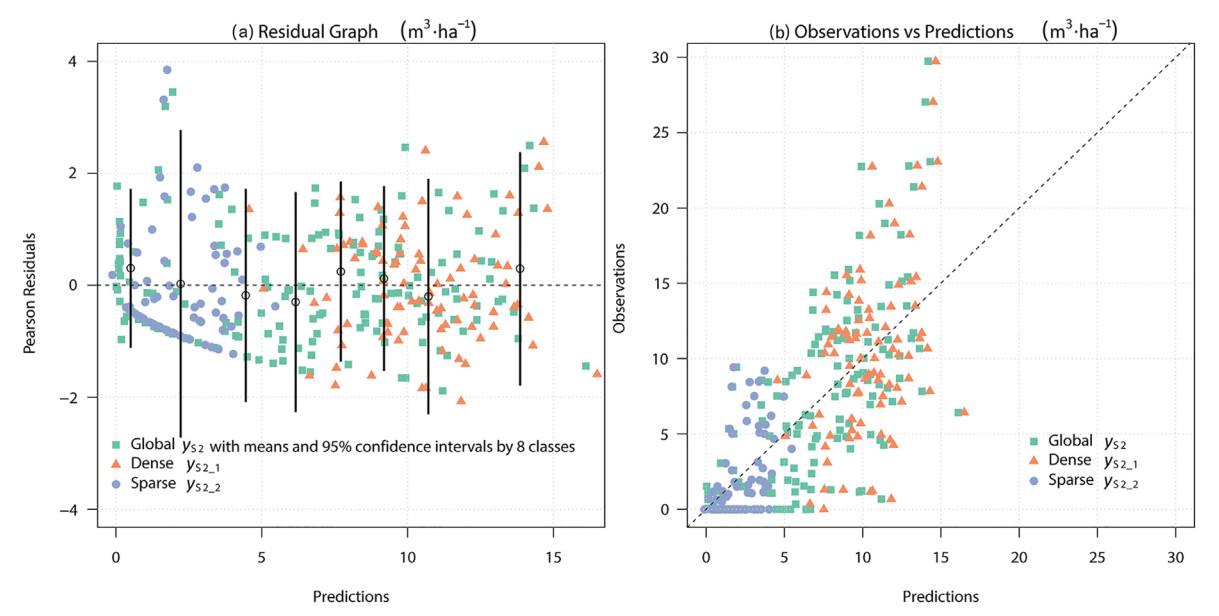
Table 4 summarizes the global model constructed with , the dense-stratum model with , and the sparse-stratum model with . No model exhibits any systematic lack of fit, as indicated by the absence of trends in the residual diagnostic graph, as shown in Fig. 5. The dense-stratum model has the highest prediction accuracy rank in RMSE, followed by the global model, and the sparse model. The global model was utilized across all estimators, encompassing the CMB estimator for wall-to-wall X, as well as Hybrid estimators for sample-based X. Conversely, the stratum-specific models were exclusively applied to the Hybrid estimator for stratified sampling of X.
Figure
5.
Graphs of residuals and predicted versus observed values for the different models.
4.3
Total remote sensing coverage outperformed by remote sensing sampling
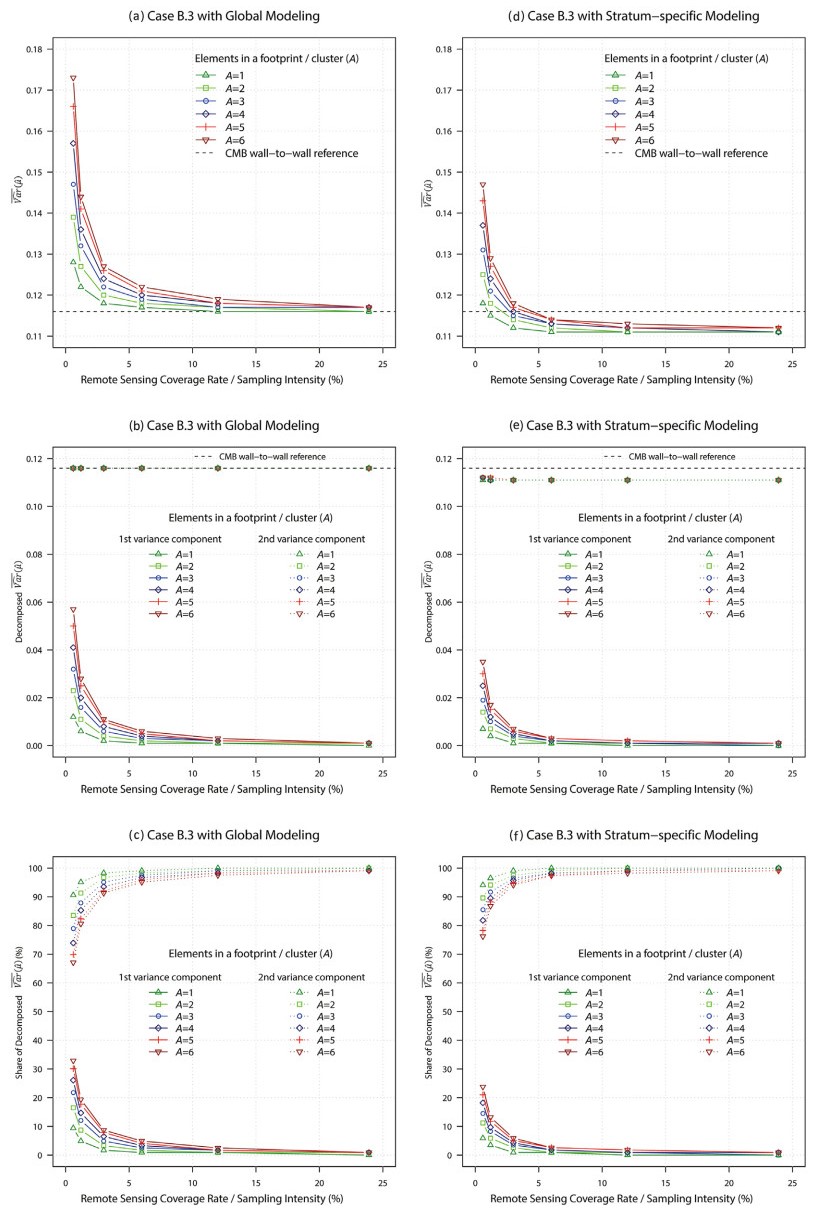
The influence of remote sensing sampling, coverage, and cluster size on inference is documented in Appendix C with generalizability discussed in Appendix D. Fig. 6 presents a summary of the results obtained from Hybrid estimation for the stratified sampling of X using global or stratum-specific modeling. The variance is decomposed for sampling and modeling components, and there are four relevant findings.
Figure
6.
Hybrid estimation for stratified sampling of X using global or stratum-specific modeling based on Appendix B.
First, using stratified sampling for X can be more efficient than conducting a complete survey of X. The Hybrid estimator for stratified sampling of X, incorporating stratum-specific modeling at 6% coverage, started to demonstrate higher precision compared to the CMB estimator at 100% coverage (Fig. 6d). The variance of the Hybrid estimator with stratum-specific modeling is not only smaller than its counterpart using a global model, but it was also smaller than that of the CMB estimator with full RS coverage (Fig. 6d, e, f; Appendix). However, the main reason is not that stratum-specific models are significantly superior to the global model. As shown in Table 4, the sparse-stratum model performed twice as poorly as the global model. Both the omission of cross-stratum covariances and the stratum-specific weighting contribute to this finding. The cross-stratum covariance in the second term of Eq. 8 is zero when stratum-specific models are used and non-zero when a global model is applied. This discovery suggests a new perspective on remote sensing instrument, acquisition, and cost for planning remote sensing-assisted forest inventories. For instance, when considering the cost of planning extensive area monitoring, it may be more beneficial to obtain non-wall-to-wall UAV or LiDAR samples through stratified sampling, instead of acquiring wall-to-wall RS data for the entire population with average quality.
Second, large-scale forest inventory may not necessarily require extensive RS coverage. As the RS coverage rate increases, the sampling variance X converges to zero in a reverse J-shaped pattern, with cost-effective sample size in our case at 12%, indicating little need for wall-to-wall coverage of X (Fig. 6a, b, c; Appendix); the variance of the Hybrid estimator with a global model converges to the variance of the CMB estimator, consistent with the analytical finding that the CMB estimator is a special case of Hybrid estimation when applying wall-to-wall coverage. The optimal sample size of X resides at the turning point of this reverse J-shaped curve, which is, however, affected by the RS cluster size. For a given RS coverage rate, small cluster sizes are preferred. The larger the cluster size, the lower the precision, a pattern particularly noticeable at low coverages. In this study, we only discuss the scenario where the cluster sizes are equal. For cases where the cluster sizes are unequal, we refer to Ståhl et al. (2011). In general, both the CMB estimator and wall-to-wall coverage can be effectively replaced with Hybrid estimation and non-wall-to-wall coverage, which will reduce costs and improve the versatility of using cutting-edge remote sensing instruments for forest inventory. A similar remark was made for the HMB estimator in Chen et al. (2023). That said, we recognize that wall-to-wall coverage may still be required for other objectives such as cartography.
Third, the variance component of modeling, rather than sampling X, dominates the total variance. While the sampling variance decreased as the coverage rate for X increased, as expected and consistent with design-based inference (Hou et al., 2022; Xu et al., 2021), the modeling variance remained stable at a high level. This suggests that the reduction of uncertainty in modeling depends on increasing the sample size for y (i.e. the S2 sample) rather than X. Additionally, stratum-specific modeling effectively reduced both variance components. To further enhance precision, modeling is crucial by (1) increasing the sample size for y, (2) incorporating more correlated X data such as from LiDAR, (3) using stratum-specific models, and (4) refining the mathematical model form.
Fourth, the use of stratum-specific modeling offers greater flexibility and efficiency compared to global modeling. Stratum-specific modeling can result in both superior and inferior stratum-specific models relative to the global model, but it ultimately yields higher precision. This is due to the impact of good or poor models being amplified or discounted by the stratum-specific weights (Eqs. 7 and 8), leading to five implications for optimizing the sampling strategy: (1) strata with larger weights require superior stratum-specific models compared to the global model; (2) a poor stratum-specific model with a smaller weight may not significantly affect ; (3) if all stratum-specific models are good, decreases further, thereby increasing precision; (4) stratification is crucial for optimizing weights and estimation; and (5) stratum-specific modeling is versatile, allowing for the use of stratum-specific RS instruments, independent variables, and models, which enhances cost-efficiency, the reuse of existing models, and most importantly, the incorporation of county-wise models into the estimation of province-wise parameters where a county is a domain or stratum of a province in NFI programs (Czaplewski, 2023).
In the context of stratification, either independence or correlation between strata is propagated through modeling. A stratum-specific model maintains independence without the necessity to combine cross-stratum covariances. Conversely, when a global model applies to each stratum, these strata become correlated due to shared model structure and parameters, necessitating the aggregation of cross-stratum covariances. This aggregation is represented in the double summation of the second term in Eq. 8. This above is the feature of the Hybrid estimator for stratified sampling of X, rather than a feature stemming from model selection.
5.
Conclusions
The study presents eight key findings: (1) the CMB estimator for wall-to-wall X is a specific instance of the Hybrid estimator for simple random sampling of X; (2) the Hybrid estimator for simple random sampling of X is a specific instance of the Hybrid estimator for cluster sampling of X; (3) the Hybrid estimator for simple random sampling of X is a specific instance of the Hybrid estimator for stratified sampling of X; (4) the Hybrid estimator for cluster sampling of X is a specific instance of the Hybrid estimator for stratified sampling of X; (5) for a given RS coverage rate, the larger the RS cluster size the lower the precision, a pattern particularly noticeable at small RS coverage rates, indicating that a small cluster size is preferred; (6) as RS coverage rate increases, the variance of Hybrid estimators converges to that of the CMB estimator in a reverse J-shaped pattern, with cost-effective sample size in our case at about 12%, indicating little need for wall-to-wall X; and (7) an interesting observation was that the Hybrid estimator for stratified sampling of X, with stratum-specific modeling, already at 6% coverage began to show higher precisions than the CMB estimator at 100% coverage, suggesting that non-wall-to-wall but stratified sampling outperformed wall-to-wall acquisition; (8) the variance component due to modeling dominated the overall uncertainty, implying that increasing the sample size of y, using advanced X such as LiDAR, and employing alternative model forms or modeling techniques are worthy directions to explore for variance reduction. Overall, Hybrid estimation strikes a balance between cost-efficiency and flexibility for large-scale monitoring based on remote sensing data.
Data availability
Data are available on request from the authors.
CRediT authorship contribution statement
Yan Zheng: Writing – review & editing, Writing – original draft, Software, Formal analysis, Data curation, Conceptualization. Zhengyang Hou: Writing – review & editing, Writing – original draft, Validation, Supervision, Software, Resources, Project administration, Methodology, Investigation, Funding acquisition, Formal analysis, Data curation, Conceptualization. Göran Ståhl: Writing – review & editing, Writing – original draft, Validation, Methodology, Investigation, Formal analysis. Ronald E. McRoberts: Writing – review & editing, Writing – original draft, Validation, Methodology, Investigation, Formal analysis. Weisheng Zeng: Writing – review & editing, Writing – original draft, Validation, Investigation, Formal analysis. Erik Næsset: Writing – original draft, Validation, Investigation, Formal analysis. Terje Gobakken: Writing – original draft, Validation, Investigation, Formal analysis. Bo Li: Writing – original draft, Validation, Investigation, Formal analysis. Qing Xu: Writing – review & editing, Writing – original draft, Resources, Methodology, Investigation, Funding acquisition, Formal analysis, Conceptualization.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
We express our gratitude to Dr. Janne Heiskanen from the University of Helsinki and the Building Biocarbon and Rural Development in West Africa (BIODEV) project for managing and supporting the fieldwork in Burkina Faso.
Bechtold, W.A., Patterson, P.L., 2005. The Enhanced Forest Inventory and Analysis Program-National Sampling Design and Estimation Procedures. USDA Forest Service, Southern Research Station.
Brännlund, R., Sidibe, A., Gong, P., 2009. Participation to forest conservation in National Kabore Tambi Park in Southern Burkina Faso. For. Policy Econ. 11, 468-474.
Carroll, R., Ruppert, D., 1988. Transformation and Weighting in Regression. Chapman & Hall/CRC, New York.
Chambers, R.L., Clark, R., 2012. An Introduction to Model-Based Survey Sampling with Applications. Oxford University Press, New York.
Chave, J., Andalo, C., Brown, S., Cairns, M., Chambers, J., Eamus, D., Fölster, H., Fromard, F., Higuchi, N., Kira, T., Lescure, J.P., Nelson, B.W., Ogawa, H., Puig, H., Riéra, B., Yamakura, T., 2005. Tree allometry and improved estimation of carbon stocks and balance in tropical forests. Oecologia 145, 87-99.
Chen, F., Hou, Z., Saarela, S., McRoberts, R.E., Ståhl, G., Kangas, A., Packalen, P., Li, B., Xu, Q., 2023. Leveraging remotely sensed non-wall-to-wall data for wall-to-wall upscaling in forest inventory. Int. J. Appl. Earth Observ. Geoinform. 119, 103314.
Cochran, W.G., 1977. Sampling Techniques. John Wiley & Sons, New York.
COP 21, 2015. Paris agreement. . (Accessed 13 February 2024).
Czaplewski, R.L., 2023. Generalized Multivariate Difference Estimator (GMDe): The Recursive Algorithm, Second Edition. Aurora, CO, Environmetrika, p. 242. Technical Report TR2023-1.
Daniel, J., 2011. Sampling Essentials: Practical Guidelines for Making Sampling Choices. Sage Publications, California.
Faber J., Fonseca L.M. 2014. How sample size influences research outcomes. Dental. Press. J. Orthod. 19, 27-29.
FAO, 2024. Areas of work: NFI. . (Accessed 13 February 2024).
Furno, M., 1996. Small sample behavior of a robust heteroskedasticity consistent covariance matrix estimator. J. Stat. Comput. Simulat. 54, 115-128.
Grafström, A., Schelin, L., 2014. How to select representative samples. Scand. J. Stat. 41, 277-290.
Graubard, B.I., Korn, E.L., 2002. Inference for superpopulation parameters using sample surveys. Stat. Sci. 17, 73-196.
Gregoire, T.G., 1998. Design-based and model-based inference in survey sampling: appreciating the difference. Can. J. For. Res. 28, 1429-1447.
Gregoire, T.G., Valentine, H.T., 2007. Sampling Strategies for Natural Resources and the Environment. CRC Press, New York.
Hansen, M.H., Madow, W.G., Tepping, B.J., 1983. An evaluation of model-dependent and probability-sampling inferences in sample surveys. J. Am. Stat. Assoc. 776-793.
Haralick, R.M., Shanmugam, K., Dinstein, I.H., 1973. Textural features for image classification. IEEE Transactions on Systems, Man, and Cybernetics, 610-621.
Harrison, R.L., 2010. Introduction to Monte Carlo simulation. AIP Conf. Proc., 17-21.
Hou, Z., Domke, G.M., Russell, M.B., Coulston, J.W., Nelson, M.D., Xu, Q., McRoberts, R.E., 2021. Updating annual state-and county-level forest inventory estimates with data assimilation and FIA data. For. Ecol. Manag. 483, 118777.
Hou, Z., McRoberts, R.E., Ståhl, G., Packalen, P., Greenberg, J.A., Xu, Q., 2018. How much can natural resource inventory benefit from finer resolution auxiliary data? Remote Sens. Environ. 209, 31-40.
Hou, Z., Yuan, K., Ståhl, G., McRoberts, R.E., Kangas, A., Tang, H., Jiang, J., Meng, J., Xu, Q., Li, Z., 2023. Conjugating remotely sensed data assimilation and model-assisted estimation for efficient multivariate forest inventory. Remote Sens. Environ. 299, 113854.
IPCC, 2018. Global warming of 1.5 ℃. . (Accessed 13 February 2024).
Kalos, M.H., Whitlock, P.A., 2009. Monte Carlo Methods. John Wiley & Sons.
McRoberts, R.E., 2006. A model-based approach to estimating forest area. Remote Sens. Environ. 103, 56-66.
McRoberts, R. E., Chen, Q., Domke, G. M., Ståhl, G., Saarela, S., Westfall, J. A., 2016. Hybrid estimators for mean aboveground carbon per unit area. For. Ecol. Manag. 378, 44-56.
McRoberts, R.E., Næsset, E., Gobakken, T., 2013. Inference for lidar-assisted estimation of forest growing stock volume. Remote Sens. Environ. 128, 268-275.
McRoberts, R.E., Nasset, E., Gobakken, T., Chirici, G., Condés, S., Hou, Z., Saarela, S., Chen, Q., Ståhl, G., Walters, B.F., 2018. Assessing components of the model-based mean square error estimator for remote sensing assisted forest applications. Can. J. For. Res. 48, 642-649. .
McRoberts, R.E, Næsset, E, Hou, Z., Ståhl, G., Saarela, S., Esteban, J., Travaglini, D., Mohammadi, J., Chirici, G., 2023, How many bootstrap replications are necessary for estimating remote sensing-assisted, model-based standard errors? Remote Sens. Environ 288, 113455.
Næsset, E., Bollandsås, O. M., Gobakken, T., Gregoire, T. G., Ståhl, G., 2013. Model-assisted estimation of change in forest biomass over an 11 year period in a sample survey supported by airborne LiDAR: a case study with post-stratification to provide “activity data.” Remote Sens. Environ. 128, 299-314.
Patterson, P.L., Healey, S.P., Ståhl, G., Saarela, S., Holm, S., Andersen, H.-E., Dubayah, R.O., Duncanson, L., Hancock, S., Armston, J., 2019. Statistical properties of hybrid estimators proposed for GEDI-NASA’s global ecosystem dynamics investigation. Environ. Res. Lett. 14, 065007.
Richards, J.A., 2022. Remote Sensing Digital Image Analysis. Springer.
Rizopoulos, D., 2022. Model selection by bootstrapping the stepAIC procedure. . (Accessed 13 February 2024).
Rother, C., Kolmogorov, V., Blake, A., 2004. GrabCut: interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. 23, 309-314.
Särndal, C.E., Swensson, B., Wretman, J.H., 1992. Model Assisted Survey Sampling. Springer, New York.
Saarela, S., Holm, S., Healey, S.P., Patterson, P.L., Yang, Z., Anderson, H.E, Dubayah, R.O., Qi, W., Duncanson, L.I., Armston, J.D., Gobakken, T., Næsset, E., Ekström, M., Ståhl, G., 2022. Comparing frameworks for biomass prediction for the global ecosystem dynamics investigation. Remote Sens. Environ. 278, 113074.
Saarela, S., Wästlund, A., Holmström, E., Mensah, A.A., Holm, S., Nilsson, M., Fridman, J., Ståhl, G., 2020. Mapping aboveground biomass and its prediction uncertainty using LiDAR and field data, accounting for tree-level allometric and LiDAR model errors. Forest Ecosyst. 7, 1-17.
Silva, A., Singh, A., Swami, A., 2018. Spectral algorithms for temporal graph cuts. In: Proceedings of the 2018 World Wide Web Conference, pp. 519–528. Lyon, France.
Ståhl, G., Holm, S., Gregoire, T.G., Gobakken, T., Næsset, E., Nelson, R., 2011. Model-based inference for biomass estimation in a LiDAR sample survey in Hedmark County, Norway. Can. J. For. Res. 41, 96-107.
Ståhl, G., Saarela, S., Schnell, S., Holm, S., Breidenbach, J., Healey, S.P., Patterson, P.L., Magnussen, S., Næsset, E., McRoberts, R.E., 2016. Use of models in large-area forest surveys: comparing model-assisted, model-based and hybrid estimation. Forest Ecosyst. 3, 1-11.
Thompson, S., 2012. Sampling, third ed. John Wiley & Sons, Hoboken. New Jersey, USA.
Tomppo, E., Gschwantner, T., Lawrence, M., McRoberts, R.E., 2010. National Forest Inventories: pathways for common reporting. Eur. Sci. Found. 1, 541-553.
Vågen, T., Winowiecki, L., Tondoh, J.E., 2013. Land degradation surveillance Framework (LDSF): field guide. . (Accessed 13 February 2024).
Vandendijck, Y., Faes, C., Kirby, R.S., Lawson, A., Hens, N., 2016. Model-based inference for small area estimation with sampling weights. Spat. Stat. 18, 455-473.
Vidal, C., Alberdi, I., Hernández, L., Redmond, J., 2016. National Forest Inventories: Assessment of Wood Availability and Use. Springer, Cham, Switzerland.

 DownLoad:
DownLoad:





 Email Alerts
Email Alerts RSS Feeds
RSS Feeds